Class DefaultRetrievalAugmentor
java.lang.Object
dev.langchain4j.rag.DefaultRetrievalAugmentor
- All Implemented Interfaces:
RetrievalAugmentor
The default implementation of
It's important to note that while efforts will be made to avoid breaking changes, the default behavior of this class may be updated in the future if it's found that the current behavior does not adequately serve the majority of use cases. Such changes would be made to benefit both current and future users.
This implementation is inspired by this article and this paper. It is recommended to review these resources for a better understanding of the concept.
This implementation orchestrates the flow between the following base components:
For each base component listed above, we offer several ready-to-use implementations, each based on a recognized approach. We intend to introduce more such implementations over time and welcome your contributions.
The flow is as follows:
1. A
2. Each
3. All
4. Lastly, a final list of
By default, each base component (except for
When there is only a single
RetrievalAugmentor intended to be suitable for the majority of use cases.
It's important to note that while efforts will be made to avoid breaking changes, the default behavior of this class may be updated in the future if it's found that the current behavior does not adequately serve the majority of use cases. Such changes would be made to benefit both current and future users.
This implementation is inspired by this article and this paper. It is recommended to review these resources for a better understanding of the concept.
This implementation orchestrates the flow between the following base components:
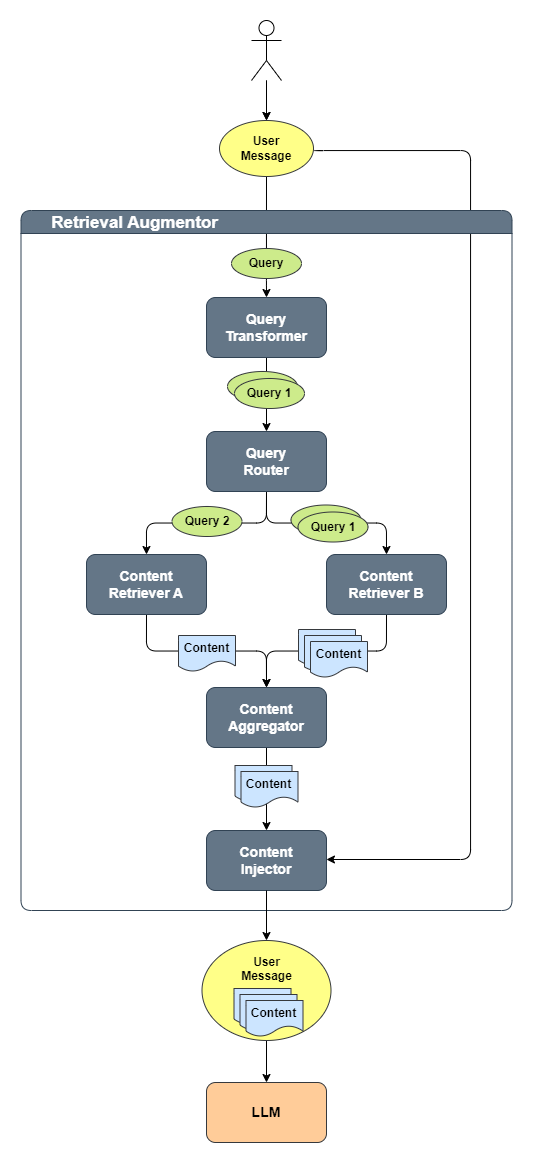
-Visual representation of this flow can be found here.QueryTransformer-QueryRouter-ContentRetriever-ContentAggregator-ContentInjector
{kind=link}
For each base component listed above, we offer several ready-to-use implementations, each based on a recognized approach. We intend to introduce more such implementations over time and welcome your contributions.
The flow is as follows:
1. A
Query (derived from an original UserMessage) is transformed
using a QueryTransformer into one or multiple Querys.
2. Each
Query is routed to the appropriate ContentRetriever using a QueryRouter.
Each ContentRetriever retrieves one or multiple Contents using a Query.
3. All
Contents retrieved by all ContentRetrievers using all Querys are
aggregated (fused/re-ranked/filtered/etc.) into a final list of Contents using a ContentAggregator.
4. Lastly, a final list of
Contents is injected into the original UserMessage
using a ContentInjector.
By default, each base component (except for
ContentRetriever, which needs to be provided by you)
is initialized with a sensible default implementation:
-Nonetheless, you are encouraged to use one of the advanced ready-to-use implementations or create a custom one.DefaultQueryTransformer-DefaultQueryRouter-DefaultContentAggregator-DefaultContentInjector
When there is only a single
Query and a single ContentRetriever,
query routing and content retrieval are performed in the same thread.
Otherwise, an Executor is used to parallelize the processing.
By default, a modified (keepAliveTime is 1 second instead of 60 seconds) Executors.newCachedThreadPool()
is used, but you can provide a custom Executor instance.- See Also:
-
Nested Class Summary
Nested ClassesModifier and TypeClassDescriptionstatic class -
Constructor Summary
ConstructorsConstructorDescriptionDefaultRetrievalAugmentor(QueryTransformer queryTransformer, QueryRouter queryRouter, ContentAggregator contentAggregator, ContentInjector contentInjector, Executor executor) -
Method Summary
-
Constructor Details
-
DefaultRetrievalAugmentor
public DefaultRetrievalAugmentor(QueryTransformer queryTransformer, QueryRouter queryRouter, ContentAggregator contentAggregator, ContentInjector contentInjector, Executor executor)
-
-
Method Details
-
augment
Description copied from interface:RetrievalAugmentor- Specified by:
augmentin interfaceRetrievalAugmentor- Parameters:
augmentationRequest- TheAugmentationRequestcontaining theChatMessageto augment.- Returns:
- The
AugmentationResultcontaining the augmentedChatMessage.
-
builder
-