RAG (Retrieval-Augmented Generation)
LLM's knowledge is limited to the data it has been trained on. If you want to make an LLM aware of domain-specific knowledge or proprietary data, you can:
- Use RAG, which we will cover in this section
- Fine-tune the LLM with your data
- Combine both RAG and fine-tuning
What is RAG?
Simply put, RAG is the way to find and inject relevant pieces of information from your data into the prompt before sending it to the LLM. This way LLM will get (hopefully) relevant information and will be able to reply using this information, which should reduce the probability of hallucinations.
Relevant pieces of information can be found using various information retrieval methods. The most popular are:
- Full-text (keyword) search. This method uses techniques like TF-IDF and BM25 to search documents by matching the keywords in a query (e.g., what the user is asking) against a database of documents. It ranks results based on the frequency and relevance of these keywords in each document.
- Vector search, also known as "semantic search". Text documents are converted into vectors of numbers using embedding models. It then finds and ranks documents based on the cosine similarity or other similarity/distance measures between the query vector and document vectors, thus capturing deeper semantic meanings.
- Hybrid. Combining multiple search methods (e.g., full-text + vector) usually improves the effectiveness of the search.
Currently, this page focuses mostly on vector search.
Full-text and hybrid search are currently supported only by Azure AI Search integration and Elasticsearch,
see AzureAiSearchContentRetriever and ElasticsearchContentRetriever for more details.
We plan to expand the RAG toolbox to include full-text and hybrid search in the near future.
RAG Stages
The RAG process is divided into 2 distinct stages: indexing and retrieval. LangChain4j provides tooling for both stages.
Indexing
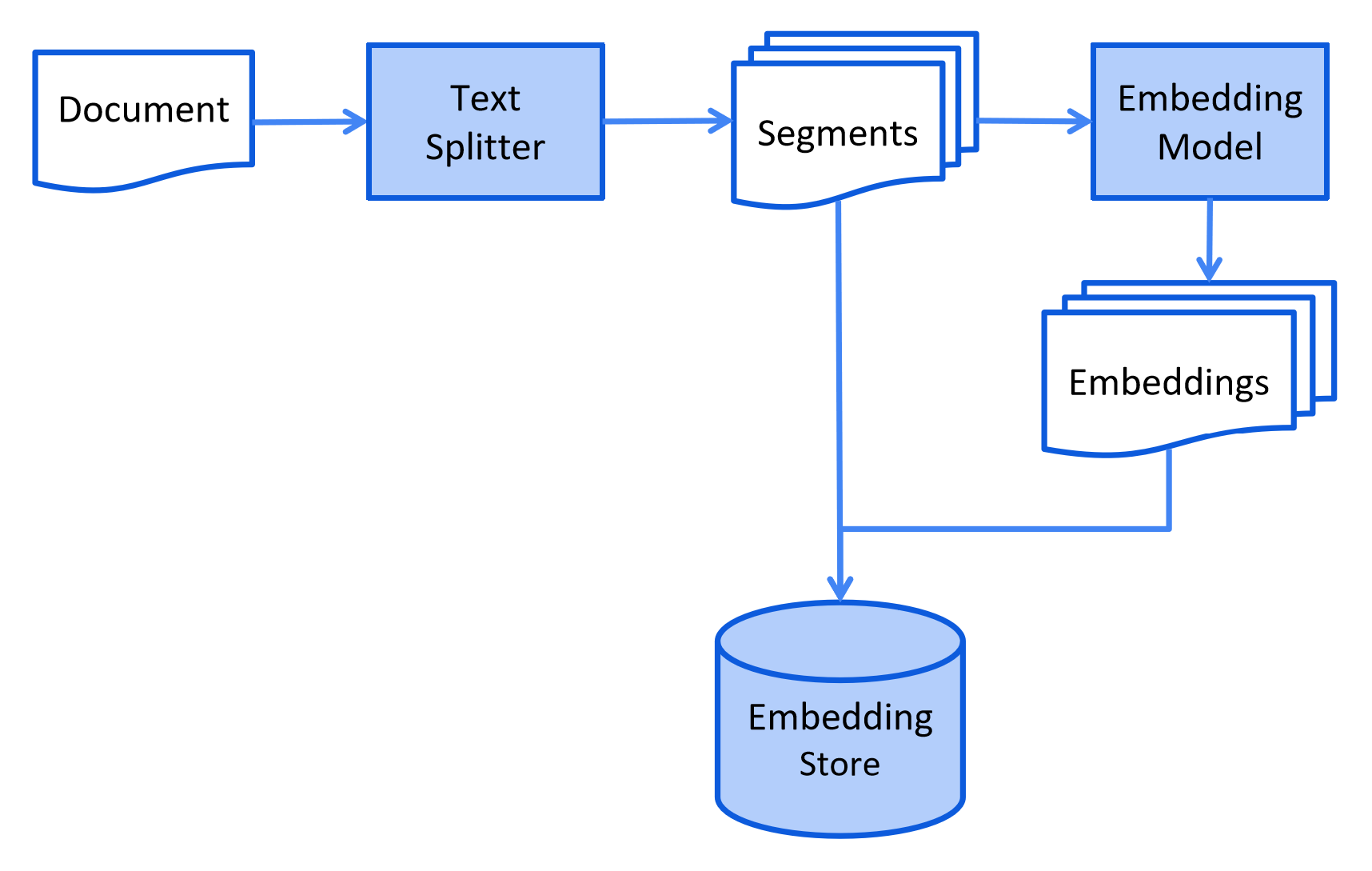
During the indexing stage, documents are pre-processed in a way that enables efficient search during the retrieval stage.
This process can vary depending on the information retrieval method used. For vector search, this typically involves cleaning the documents, enriching them with additional data and metadata, splitting them into smaller segments (aka chunking), embedding these segments, and finally storing them in an embedding store (aka vector database).
The indexing stage usually occurs offline, meaning it does not require end users to wait for its completion. This can be achieved through, for example, a cron job that re-indexes internal company documentation once a week during the weekend. The code responsible for indexing can also be a separate application that only handles indexing tasks.
However, in some scenarios, end users may want to upload their custom documents to make them accessible to the LLM. In this case, indexing should be performed online and be a part of the main application.
Here is a simplified diagram of the indexing stage:
Retrieval
The retrieval stage usually occurs online, when a user submits a question that should be answered using the indexed documents.
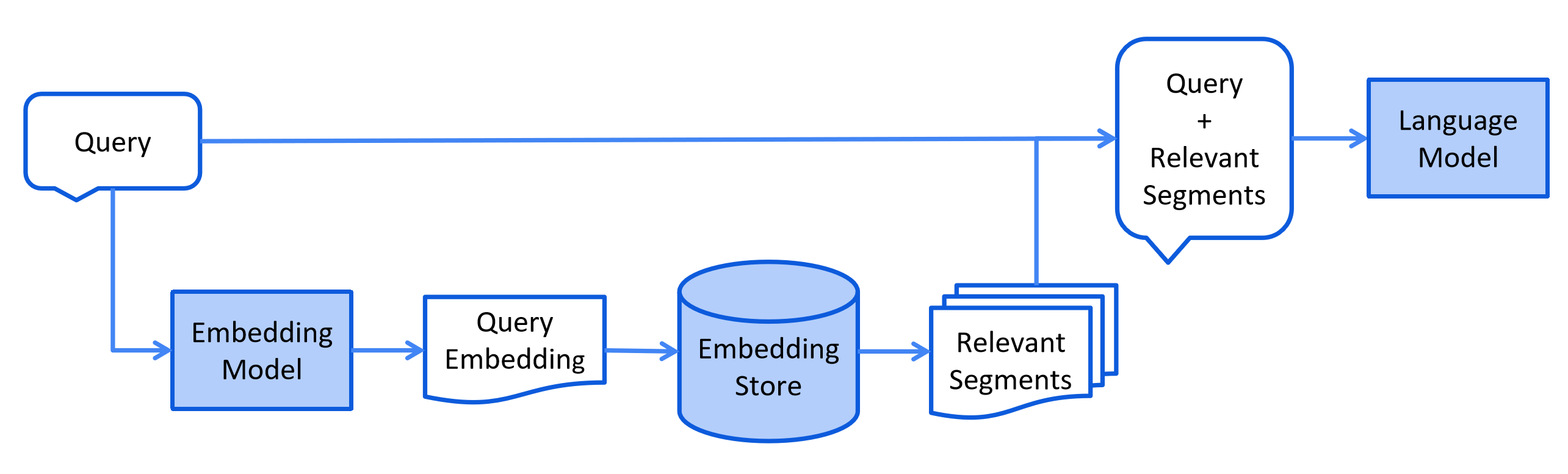
This process can vary depending on the information retrieval method used. For vector search, this typically involves embedding the user's query (question) and performing a similarity search in the embedding store. Relevant segments (pieces of the original documents) are then injected into the prompt and sent to the LLM.
Here is a simplified diagram of the retrieval stage:
RAG Flavours in LangChain4j
LangChain4j offers three flavors of RAG:
- Easy RAG: the easiest way to start with RAG
- Naive RAG: a basic implementation of RAG using vector search
- Advanced RAG: a modular RAG framework that allows for additional steps such as query transformation, retrieval from multiple sources, and re-ranking
Easy RAG
LangChain4j has an "Easy RAG" feature that makes it as easy as possible to get started with RAG. You don't have to learn about embeddings, choose a vector store, find the right embedding model, figure out how to parse and split documents, etc. Just point to your document(s), and LangChain4j will do its magic.
If you need a customizable RAG, skip to the next section.
If you are using Quarkus, there is an even easier way to do Easy RAG. Please read Quarkus documentation.
The quality of such "Easy RAG" will, of course, be lower than that of a tailored RAG setup. However, this is the easiest way to start learning about RAG and/or make a proof of concept. Later, you will be able to transition smoothly from Easy RAG to more advanced RAG, adjusting and customizing more and more aspects.
- Import the
langchain4j-easy-ragdependency:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.11.9-beta19</version>
</dependency>
- Let's load your documents:
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");
This will load all files from the specified directory.
What is happening under the hood?
The Apache Tika library, which supports a wide variety of document types,
is used to detect document types and parse them.
Since we did not explicitly specify which DocumentParser to use,
the FileSystemDocumentLoader will load an ApacheTikaDocumentParser,
provided by langchain4j-easy-rag dependency through SPI.
How to customize loading documents?
If you want to load documents from all subdirectories, you can use the loadDocumentsRecursively method:
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("/home/langchain4j/documentation");
Additionally, you can filter documents by using a glob or regex:
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.pdf");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation", pathMatcher);
When using loadDocumentsRecursively method, you might want to use a double asterisk (instead of a single one)
in glob: glob:**.pdf.
- Now, we need to preprocess and store documents in a specialized embedding store, also known as vector database. This is necessary to quickly find relevant pieces of information when a user asks a question. We can use any of our 30+ supported embedding stores, but for simplicity, we will use an in-memory one:
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
What is happening under the hood?
-
The
EmbeddingStoreIngestorloads aDocumentSplitterfrom thelangchain4j-easy-ragdependency through SPI. EachDocumentis split into smaller pieces (TextSegments) each consisting of no more than 300 tokens and with a 30-token overlap. -
The
EmbeddingStoreIngestorloads anEmbeddingModelfrom thelangchain4j-easy-ragdependency through SPI. EachTextSegmentis converted into anEmbeddingusing theEmbeddingModel.
We have chosen bge-small-en-v1.5 as the default embedding model for Easy RAG. It has achieved an impressive score on the MTEB leaderboard, and its quantized version occupies only 24 megabytes of space. Therefore, we can easily load it into memory and run it in the same process using ONNX Runtime.
Yes, that's right, you can convert text into embeddings entirely offline, without any external services, in the same JVM process. LangChain4j offers some popular embedding models out-of-the-box.
- All
TextSegment-Embeddingpairs are stored in theEmbeddingStore.
- The last step is to create an AI Service that will serve as our API to the LLM:
interface Assistant {
String chat(String userMessage);
}
ChatModel chatModel = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
Here, we configure the Assistant to use an OpenAI LLM to answer user questions,
remember the 10 latest messages in the conversation,
and retrieve relevant content from an EmbeddingStore that contains our documents.
- And now we are ready to chat with it!
String answer = assistant.chat("How to do Easy RAG with LangChain4j?");
Core RAG APIs
LangChain4j offers a rich set of APIs to make it easy for you to build custom RAG pipelines, ranging from simple ones to advanced ones. In this section, we will cover the main domain classes and APIs.
Document
A Document class represents an entire document, such as a single PDF file or a web page.
At the moment, the Document can only represent textual information,
but future updates will enable it to support images and tables as well.
Useful methods
Document.text()returns the text of theDocumentDocument.metadata()returns theMetadataof theDocument(see "Metadata" section below)Document.toTextSegment()converts theDocumentinto aTextSegment(see "TextSegment" section below)Document.from(String, Metadata)creates aDocumentfrom text andMetadataDocument.from(String)creates aDocumentfrom text with emptyMetadata
Metadata
Each Document contains Metadata.
It stores meta information about the Document, such as its name, source, last update date, owner,
or any other relevant details.
The Metadata is stored as a key-value map, where the key is of the String type,
and the value can be one of the following types: String, Integer, Long, Float, Double, UUID.
Metadata is useful for several reasons:
- When including the content of the
Documentin a prompt to the LLM, metadata entries can also be included, providing the LLM with additional information to consider. For example, providing theDocumentname and source can help improve the LLM's understanding of the content. - When searching for relevant content to include in the prompt,
one can filter by
Metadataentries. For example, you can narrow down a semantic search to onlyDocuments belonging to a specific owner. - When the source of the
Documentis updated (for example, a specific page of documentation), one can easily locate the correspondingDocumentby its metadata entry (for example, "id", "source", etc.) and update it in theEmbeddingStoreas well to keep it in sync.
Useful methods
Metadata.from(Map)createsMetadatafrom aMapMetadata.put(String key, String value)/put(String, int)/ etc., adds an entry to theMetadataMetadata.putAll(Map)adds multiple entries to theMetadataMetadata.getString(String key)/getInteger(String key)/ etc., returns a value of theMetadataentry, casting it to the required typeMetadata.containsKey(String key)checks whetherMetadatacontains an entry with the specified keyMetadata.remove(String key)removes an entry from theMetadataby keyMetadata.copy()returns a copy of theMetadataMetadata.toMap()convertsMetadatainto aMapMetadata.merge(Metadata)merges the currentMetadatawith anotherMetadata
Document Loader
You can create a Document from a String, but a simpler method is to use one of our document loaders included in the library:
FileSystemDocumentLoaderfrom thelangchain4jmoduleClassPathDocumentLoaderfrom thelangchain4jmoduleUrlDocumentLoaderfrom thelangchain4jmoduleAmazonS3DocumentLoaderfrom thelangchain4j-document-loader-amazon-s3moduleAzureBlobStorageDocumentLoaderfrom thelangchain4j-document-loader-azure-storage-blobmoduleGitHubDocumentLoaderfrom thelangchain4j-document-loader-githubmoduleGoogleCloudStorageDocumentLoaderfrom thelangchain4j-document-loader-google-cloud-storagemoduleSeleniumDocumentLoaderfrom thelangchain4j-document-loader-seleniummodulePlaywrightDocumentLoaderfrom thelangchain4j-document-loader-playwrightmoduleTencentCosDocumentLoaderfrom thelangchain4j-document-loader-tencent-cosmodule
Document Parser
Documents can represent files in various formats, such as PDF, DOC, TXT, etc.
To parse each of these formats, there's a DocumentParser interface with several implementations included in the library:
TextDocumentParserfrom thelangchain4jmodule, which can parse files in plain text format (e.g. TXT, HTML, MD, etc.)ApachePdfBoxDocumentParserfrom thelangchain4j-document-parser-apache-pdfboxmodule, which can parse PDF filesApachePoiDocumentParserfrom thelangchain4j-document-parser-apache-poimodule, which can parse MS Office file formats (e.g. DOC, DOCX, PPT, PPTX, XLS, XLSX, etc.)ApacheTikaDocumentParserfrom thelangchain4j-document-parser-apache-tikamodule, which can automatically detect and parse almost all existing file formatsDoclingDocumentParserfrom thelangchain4j-document-parser-doclingmodule, which uses Docling Java and Docling to process documents.MarkdownDocumentParserfrom thelangchain4j-document-parser-markdownmodule, which can parse files in markdown formatYamlDocumentParserfrom thelangchain4j-document-parser-yamlmodule, which can parse files in yaml format
Here is an example of how to load one or multiple Documents from the file system:
// Load a single document
Document document = FileSystemDocumentLoader.loadDocument("/home/langchain4j/file.txt", new TextDocumentParser());
// Load all documents from a directory
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", new TextDocumentParser());
// Load all *.txt documents from a directory
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.txt");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", pathMatcher, new TextDocumentParser());
// Load all documents from a directory and its subdirectories
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("/home/langchain4j", new TextDocumentParser());
You can also load documents without explicitly specifying a DocumentParser.
In this case, a default DocumentParser will be used.
The default one is loaded through SPI (e.g. from langchain4j-document-parser-apache-tika or langchain4j-easy-rag, if one of them is imported).
If no DocumentParsers are found through SPI, a TextDocumentParser is used as a fallback.
Document Transformer
DocumentTransformer implementations can perform a variety of document transformations such as:
- Cleaning: This involves removing unnecessary noise from the
Document's text, which can save tokens and reduce distractions. - Filtering: to completely exclude particular
Documents from the search. - Enriching: Additional information can be added to
Documents to potentially enhance search results. - Summarizing: The
Documentcan be summarized, and its short summary can be stored in theMetadatato be later included in eachTextSegment(which we will cover below) to potentially improve the search. - Etc.
Metadata entries can also be added, modified, or removed at this stage.
Currently, the only implementation provided out-of-the-box is HtmlToTextDocumentTransformer
in the langchain4j-document-transformer-jsoup module,
which can extract desired text content and metadata entries from the raw HTML.
Since there is no one-size-fits-all solution, we recommend implementing your own DocumentTransformer,
tailored to your unique data.
Graph Transformer
GraphTransformer is an interface that converts unstructured Document objects into structured GraphDocuments by extracting semantic graph elements such as nodes and relationships.
It is ideal for converting raw text into structured semantic graphs
A GraphTransformer transforms raw documents into GraphDocuments. These include:
- A set of nodes (
GraphNode) representing entities or concepts in the text. - A set of relationships (
GraphEdge) representing how those entities are connected. - The original
Documentas thesource.
The default implementation is LLMGraphTransformer, which uses a language model (e.g., OpenAI) to extract graph information from natural language using prompt engineering.
Key Benefits
- Entity and Relationship Extraction: Identify key concepts and their semantic connections.
- Graph Representation: Output is ready for integration into knowledge graphs or graph databases.
- Model-Powered Parsing: Uses a large language model to infer structure from unstructured text.
Maven Dependency
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-llm-graph-transformer</artifactId>
<version>${latest version here}</version>
</dependency>
Example Usage
import dev.langchain4j.data.document.Document;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.community.data.document.graph.GraphDocument;
import dev.langchain4j.community.data.document.graph.GraphNode;
import dev.langchain4j.community.data.document.graph.GraphEdge;
import dev.langchain4j.community.data.document.transformer.graph.GraphTransformer;
import dev.langchain4j.community.data.document.transformer.graph.llm.LLMGraphTransformer;
import java.time.Duration;
import java.util.Set;
public class GraphTransformerExample {
public static void main(String[] args) {
// Create a GraphTransformer backed by an LLM
GraphTransformer transformer = new LLMGraphTransformer(
OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.timeout(Duration.ofSeconds(60))
.build()
);
// Input document
Document document = Document.from("Barack Obama was born in Hawaii and served as the 44th President of the United States.");
// Transform the document
GraphDocument graphDocument = transformer.transform(document);
// Access nodes and relationships
Set<GraphNode> nodes = graphDocument.nodes();
Set<GraphEdge> relationships = graphDocument.relationships();
nodes.forEach(System.out::println);
relationships.forEach(System.out::println);
}
}
Output Example
GraphNode(name=Barack Obama, type=Person)
GraphNode(name=Hawaii, type=Location)
GraphEdge(from=Barack Obama, predicate=was born in, to=Hawaii)
GraphEdge(from=Barack Obama, predicate=served as, to=President of the United States)
Text Segment
Once your Documents are loaded, it is time to split (chunk) them into smaller segments (pieces).
LangChain4j's domain model includes a TextSegment class that represents a segment of a Document.
As the name suggests, TextSegment can represent only textual information.
To split or not to split?
There are several reasons why you might want to include only a few relevant segments instead of the entire knowledge base in the prompt:
- LLMs have a limited context window, so the entire knowledge base might not fit
- The more information you provide in the prompt, the longer it takes for the LLM to process it and respond
- The more information you provide in the prompt, the more you pay
- Irrelevant information in the prompt might distract the LLM and increase the chance of hallucinations
- The more information you provide in the prompt, the harder it is to explain based on which information the LLM responded
We can address these concerns by splitting a knowledge base into smaller, more digestible segments. How big should those segments be? That is a good question. As always, it depends.
There are currently 2 widely used approaches:
- Each document (e.g., a PDF file, a web page, etc.) is atomic and indivisible. During retrieval in the RAG pipeline, the N most relevant documents are retrieved and injected into the prompt. You will most probably need to use a long-context LLM in this case since documents can be quite long. This approach is suitable if retrieving complete documents is important, such as when you can't afford to miss some details.
- Pros: No context is lost.
- Cons:
- More tokens are consumed.
- Sometimes, documents can contain multiple sections/topics, and not all of them are relevant to the query.
- Vector search quality suffers because complete documents of various sizes are compressed into a single, fixed-length vector.
- Documents are split into smaller segments, such as chapters, paragraphs, or sometimes even sentences. During retrieval in the RAG pipeline, the N most relevant segments are retrieved and injected into the prompt. The challenge lies in ensuring each segment provides sufficient context/information for the LLM to understand it. Missing context can lead to the LLM misinterpreting the given segment and hallucinating. A common strategy is to split documents into segments with overlap, but this doesn't completely solve the problem. Several advanced techniques can help here, for example, "sentence window retrieval", "auto-merging retrieval", and "parent document retrieval". We won't go into details here, but essentially, these methods help to fetch more context around the retrieved segments, providing the LLM with additional information before and after the retrieved segment.
- Pros:
- Better quality of vector search.
- Reduced token consumption.
- Cons: Some context may still be lost.
Useful methods
TextSegment.text()returns the text of theTextSegmentTextSegment.metadata()returns theMetadataof theTextSegmentTextSegment.from(String, Metadata)creates aTextSegmentfrom text andMetadataTextSegment.from(String)creates aTextSegmentfrom text with emptyMetadata
Document Splitter
LangChain4j has a DocumentSplitter interface with several out-of-the-box implementations:
DocumentByParagraphSplitterDocumentByLineSplitterDocumentBySentenceSplitterDocumentByWordSplitterDocumentByCharacterSplitterDocumentByRegexSplitter- Recursive:
DocumentSplitters.recursive(...)
They all work as follows:
- You instantiate a
DocumentSplitter, specifying the desired size ofTextSegments and, optionally, an overlap in characters or tokens. - You call the
split(Document)orsplitAll(List<Document>)methods of theDocumentSplitter. - The
DocumentSplittersplits the givenDocuments into smaller units, the nature of which varies with the splitter. For instance,DocumentByParagraphSplitterdivides a document into paragraphs (defined by two or more consecutive newline characters), whileDocumentBySentenceSplitteruses the OpenNLP library's sentence detector to split a document into sentences, and so on. - The
DocumentSplitterthen combines these smaller units (paragraphs, sentences, words, etc.) intoTextSegments, attempting to include as many units as possible in a singleTextSegmentwithout exceeding the limit set in step 1. If some of the units are still too large to fit into aTextSegment, it calls a sub-splitter. This is anotherDocumentSplittercapable of splitting units that do not fit into more granular units. AllMetadataentries are copied from theDocumentto eachTextSegment. A unique metadata entry "index" is added to each text segment. The firstTextSegmentwill containindex=0, the secondindex=1, and so on.
Text Segment Transformer
TextSegmentTransformer is similar to DocumentTransformer (described above), but it transforms TextSegments.
As with the DocumentTransformer, there is no one-size-fits-all solution,
so we recommend implementing your own TextSegmentTransformer, tailored to your unique data.
One technique that works quite well for improving retrieval is to include the Document title or a short summary
in each TextSegment.
Embedding
The Embedding class encapsulates a numerical vector that represents the "semantic meaning"
of the content that has been embedded (usually text, such as a TextSegment).
Read more about vector embeddings here:
- https://www.elastic.co/what-is/vector-embedding
- https://www.pinecone.io/learn/vector-embeddings/
- https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings
Useful methods
Embedding.dimension()returns the dimension of the embedding vector (its length)CosineSimilarity.between(Embedding, Embedding)calculates the cosine similarity between 2EmbeddingsEmbedding.normalize()normalizes the embedding vector (in place)
Embedding Model
The EmbeddingModel interface represents a special type of model that converts text into an Embedding.
Currently supported embedding models can be found here.
Useful methods
EmbeddingModel.embed(String)embeds the given textEmbeddingModel.embed(TextSegment)embeds the givenTextSegmentEmbeddingModel.embedAll(List<TextSegment>)embeds all the givenTextSegmentEmbeddingModel.dimension()returns the dimension of theEmbeddingproduced by this model
Request/response API and per-call parameters
Besides the convenience methods above, EmbeddingModel accepts an EmbeddingRequest and returns an
EmbeddingResponse, which lets you pass per-call parameters:
EmbeddingResponse response = embeddingModel.embed(EmbeddingRequest.builder()
.input("What is the capital of France?")
.inputType(EmbeddingInputType.QUERY) // query vs document, see the section below
.dimensions(256) // reduce output dimensionality (on models that support it)
.build());
List<Embedding> embeddings = response.embeddings();
Per-call parameters are strictly opt-in: each provider declares what it supports via supportedParameters().
If a request uses a parameter the model does not support, it fails fast with UnsupportedFeatureException
rather than silently ignoring it. See also
Query vs Document Embeddings.
Multimodal embeddings
Some models embed images (and interleaved text + image) into the same vector space. Build inputs from Content
parts; on models that support it (Cohere Embed v4, Voyage multimodal, Google Gemini Embedding 2, Amazon Titan
Multimodal, Jina CLIP, ...) the parts are fused into a single embedding:
EmbeddingResponse response = embeddingModel.embed(EmbeddingRequest.builder()
.input(TextContent.from("a photo of a cat"), ImageContent.from("https://example.com/cat.png"))
.build());
A model declares its supported modalities via supportedContentTypes(); passing an image to a text-only model
fails fast with UnsupportedFeatureException. EmbeddingModel observability (listeners) is described in the
Observability tutorial.
Embedding Store
The EmbeddingStore interface represents a store for Embeddings, also known as vector database.
It allows for the storage and efficient search of similar (close in the embedding space) Embeddings.
Currently supported embedding stores can be found here.
EmbeddingStore can store Embeddings alone or together with the corresponding TextSegment:
- It can store only
Embedding, by ID. Original embedded data can be stored elsewhere and correlated using the ID. - It can store both
Embeddingand the original data that has been embedded (usuallyTextSegment).
Useful methods
EmbeddingStore.add(Embedding)adds a givenEmbeddingto the store and returns a random IDEmbeddingStore.add(String id, Embedding)adds a givenEmbeddingwith a specified ID to the storeEmbeddingStore.add(Embedding, TextSegment)adds a givenEmbeddingwith an associatedTextSegmentto the store and returns a random IDEmbeddingStore.addAll(List<Embedding>)adds a list of givenEmbeddings to the store and returns a list of random IDsEmbeddingStore.addAll(List<Embedding>, List<TextSegment>)adds a list of givenEmbeddings with associatedTextSegments to the store and returns a list of random IDsEmbeddingStore.addAll(List<String> ids, List<Embedding>, List<TextSegment>)adds a list of givenEmbeddings with associated IDs andTextSegments to the storeEmbeddingStore.search(EmbeddingSearchRequest)searches for the most similarEmbeddingsEmbeddingStore.remove(String id)removes a singleEmbeddingfrom the store by IDEmbeddingStore.removeAll(Collection<String> ids)removes allEmbeddings from the store whose IDs are present in the given collection.EmbeddingStore.removeAll(Filter)removes allEmbeddings that match the specifiedFilterfrom the storeEmbeddingStore.removeAll()removes allEmbeddings from the store
EmbeddingSearchRequest
The EmbeddingSearchRequest represents a request to search in an EmbeddingStore.
It has the following attributes:
Embedding queryEmbedding: The embedding used as a reference.int maxResults: The maximum number of results to return. This is an optional parameter. Default: 3.double minScore: The minimum score, ranging from 0 to 1 (inclusive). Only embeddings with a score >=minScorewill be returned. This is an optional parameter. Default: 0.Filter filter: The filter to be applied to theMetadataduring search. OnlyTextSegments whoseMetadatamatches theFilterwill be returned.
Filter
The Filter allows filtering by Metadata entries when performing a vector search.
Currently, the following Filter types/operations are supported:
IsEqualToIsNotEqualToIsGreaterThanIsGreaterThanOrEqualToIsLessThanIsLessThanOrEqualToIsInIsNotInContainsStringAndNotOr
Not all embedding stores support filtering by Metadata,
please see the "Filtering by Metadata" column here.
Some stores that support filtering by Metadata do not support all possible Filter types/operations.
For example, ContainsString is currently supported only by Milvus, PgVector and Qdrant.
More details about Filter can be found here.
EmbeddingSearchResult
The EmbeddingSearchResult represents a result of a search in an EmbeddingStore.
It contains the list of EmbeddingMatches.
Embedding Match
The EmbeddingMatch represents a matched Embedding along with its relevance score, ID, and original embedded data (usually TextSegment).
Embedding Store Ingestor
The EmbeddingStoreIngestor represents an ingestion pipeline and is responsible for
ingesting Documents into an EmbeddingStore.
In the simplest configuration, EmbeddingStoreIngestor embeds provided Documents
using a specified EmbeddingModel and stores them, along with their Embeddings in a specified EmbeddingStore:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document1);
ingestor.ingest(document2, document3);
IngestionResult ingestionResult = ingestor.ingest(List.of(document4, document5, document6));
All ingest() methods in EmbeddingStoreIngestor return an IngestionResult.
The IngestionResult contains useful information, including TokenUsage,
which shows how many tokens were used for embedding.
Optionally, the EmbeddingStoreIngestor can transform Documents using a specified DocumentTransformer.
This can be useful if you want to clean, enrich, or format Documents before embedding them.
Optionally, the EmbeddingStoreIngestor can split Documents into TextSegments using a specified DocumentSplitter.
This can be useful if Documents are big, and you want to split them into smaller TextSegments to improve the quality
of similarity searches and reduce the size and cost of a prompt sent to the LLM.
Optionally, the EmbeddingStoreIngestor can transform TextSegments using a specified TextSegmentTransformer.
This can be useful if you want to clean, enrich, or format TextSegments before embedding them.
An example:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
// adding userId metadata entry to each Document to be able to filter by it later
.documentTransformer(document -> {
document.metadata().put("userId", "12345");
return document;
})
// splitting each Document into TextSegments of 1000 tokens each, with a 200-token overlap
.documentSplitter(DocumentSplitters.recursive(1000, 200, new OpenAiTokenCountEstimator("gpt-4o-mini")))
// adding a name of the Document to each TextSegment to improve the quality of search
.textSegmentTransformer(textSegment -> TextSegment.from(
textSegment.metadata().getString("file_name") + "\n" + textSegment.text(),
textSegment.metadata()
))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
Query vs Document Embeddings (opt-in)
Some embedding models (e.g. Cohere Embed v4, Voyage, Google) produce better retrieval quality when documents
and queries are embedded differently. You can opt in by declaring the input type: DOCUMENT on the
EmbeddingStoreIngestor (for the indexed segments) and QUERY on the EmbeddingStoreContentRetriever (for the
query, see Embedding Store Content Retriever).
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.embeddingInputType(EmbeddingInputType.DOCUMENT)
.build();
When embeddingInputType is not set, no input type is sent. When it is set, the selected EmbeddingModel must
support the input type parameter (see its supportedParameters()), otherwise embedding fails fast with
UnsupportedFeatureException.
Naive RAG
Once our documents are ingested (see previous sections), we can create
an EmbeddingStoreContentRetriever to enable naive RAG functionality.
When using AI Services, naive RAG can be configured as follows:
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5)
.minScore(0.75)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(model)
.contentRetriever(contentRetriever)
.build();
Advanced RAG
Advanced RAG can be implemented with LangChain4j with the following core components:
QueryTransformerQueryRouterContentRetrieverContentAggregatorContentInjector
The following diagram shows how these components work together:
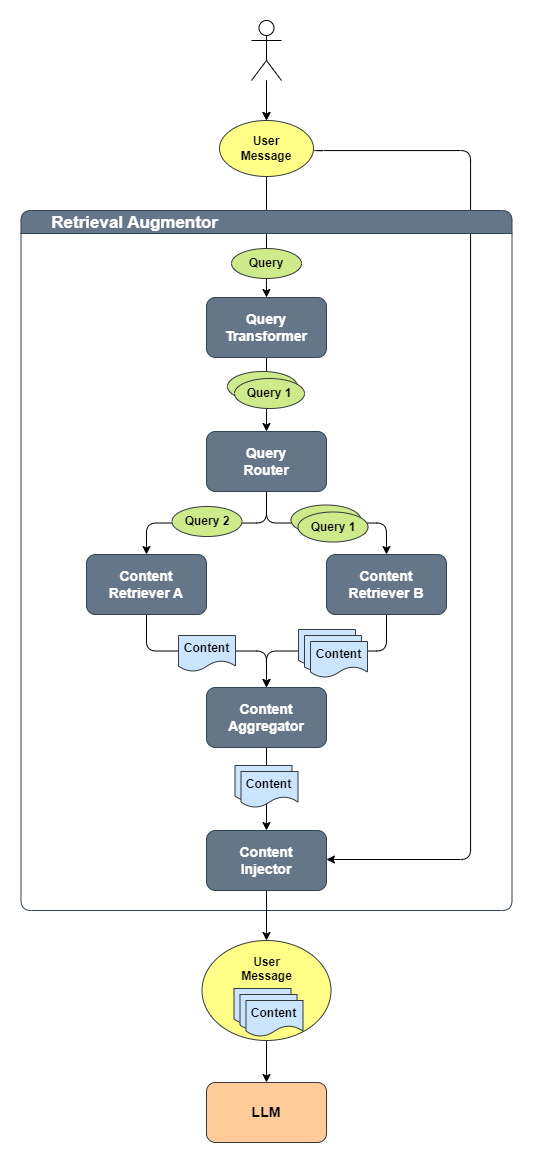
The process is as follows:
- The user produces a
UserMessage, which is converted into aQuery - The
QueryTransformertransforms theQueryinto one or multipleQuerys - Each
Queryis routed by theQueryRouterto one or moreContentRetrievers - Each
ContentRetrieverretrieves relevantContents for eachQuery - The
ContentAggregatorcombines all retrievedContents into a single final ranked list - This list of
Contents is injected into the originalUserMessage - Finally, the
UserMessage, containing the original query along with the injected relevant content, is sent to the LLM
Please refer to the Javadoc of each component for more details.
Retrieval Augmentor
RetrievalAugmentor is an entry point into the RAG pipeline.
It is responsible for augmenting a ChatMessage with relevant Contents
retrieved from various sources.
An instance of a RetrievalAugmentor can be specified during the creation of an AI Service:
Assistant assistant = AiServices.builder(Assistant.class)
...
.retrievalAugmentor(retrievalAugmentor)
.build();
Every time an AI Service is invoked, the specified RetrievalAugmentor
will be called to augment the current UserMessage.
You can use the default implementation of a RetrievalAugmentor
(described below) or implement a custom one.
Default Retrieval Augmentor
LangChain4j provides an out-of-the-box implementation of the RetrievalAugmentor interface:
DefaultRetrievalAugmentor, which should be suitable for the majority of RAG use cases.
It was inspired by this article
and this paper.
It is recommended to review these resources for a better understanding of the concept.
Query
Query represents a user query in the RAG pipeline.
It contains the text of the query and query metadata.
Query Metadata
The Metadata inside the Query contains information that might be useful in various components
of the RAG pipeline, for example:
Metadata.userMessage()- the originalUserMessagethat should be augmentedMetadata.chatMemoryId()- the value of a@MemoryId-annotated method parameter. More details here. This can be used to identify the user and apply access restrictions or filters during the retrieval.Metadata.chatMemory()- all previousChatMessages. This can help to understand the context in which theQuerywas asked.Metadata.invocationParameters()- containsInvocationParametersthat can be specified when invoking AI Service:
interface Assistant {
String chat(@UserMessage String userMessage, InvocationParameters parameters);
}
InvocationParameters parameters = InvocationParameters.from(Map.of("userId", "12345"));
String response = assistant.chat("Hello", parameters);
InvocationParameters can also be accessed within other AI Service components, such as:
@Tool-annotated methodToolProvider: inside theToolProviderRequestToolArgumentsErrorHandlerandToolExecutionErrorHandler: inside theToolErrorContext
Parameters are stored in a mutable, thread safe Map.
Data can be passed between AI Service components inside the InvocationParameters
(for example, from one RAG component to another or from a RAG component to a tool)
during a single invocation of the AI Service.
Query Transformer
QueryTransformer transforms the given Query into one or multiple Querys.
The goal is to enhance retrieval quality by modifying or expanding the original Query.
Some known approaches to improve retrieval include:
- Query compression
- Query expansion
- Query re-writing
- Step-back prompting
- Hypothetical document embeddings (HyDE)
More details can be found here.
LangChain4j also has an optional community Prompt Repetition module that provides RepeatingQueryTransformer. It repeats the retrieval query before content retrieval and should be used to transform the query itself, not the final augmented prompt sent to the model.
Default Query Transformer
DefaultQueryTransformer is the default implementation used in DefaultRetrievalAugmentor.
It does not make any modifications to the Query, it just passes it through.
Compressing Query Transformer
CompressingQueryTransformer uses an LLM to compress the given Query
and previous conversation into a standalone Query.
This is useful when the user might ask follow-up questions that refer to information
in previous questions or answers.
Here is an example:
User: Tell me about John Doe
AI: John Doe was a ...
User: Where did he live?
The query Where did he live? by itself would not be able to retrieve the needed information
because there is no explicit reference to John Doe, making it unclear who he refers to.
When using CompressingQueryTransformer, the LLM will read the entire conversation
and transform Where did he live? into Where did John Doe live?.
Expanding Query Transformer
ExpandingQueryTransformer uses an LLM to expand the given Query into multiple Querys.
This is useful because LLM can rephrase and reformulate Query in various ways,
which will help to retrieve more relevant content.
Content
Content represents the content relevant to the user Query.
Currently, it is limited to text content (i.e., TextSegment),
but in the future it may support other modalities (e.g., images, audio, video, etc.).
Content Retriever
ContentRetriever retrieves Contents from an underlying data source using a given Query.
The underlying data source can be virtually anything:
- Embedding store
- Full-text search engine
- Hybrid of vector and full-text search
- Web Search Engine
- Knowledge graph
- SQL database
- etc.
The list of Content returned by ContentRetriever is ordered by relevance, from highest to lowest.
Embedding Store Content Retriever
EmbeddingStoreContentRetriever retrieves relevant Content from the EmbeddingStore using
the EmbeddingModel to embed the Query.
Here is an example:
EmbeddingStore embeddingStore = ...
EmbeddingModel embeddingModel = ...
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3)
// maxResults can also be specified dynamically depending on the query
.dynamicMaxResults(query -> 3)
.minScore(0.75)
// minScore can also be specified dynamically depending on the query
.dynamicMinScore(query -> 0.75)
.filter(metadataKey("userId").isEqualTo("12345"))
// filter can also be specified dynamically depending on the query
.dynamicFilter(query -> {
String userId = query.metadata().invocationParameters().get("userId");
return metadataKey("userId").isEqualTo(userId);
})
.build();
interface Assistant {
String chat(@UserMessage String userMessage, InvocationParameters parameters);
}
InvocationParameters parameters = InvocationParameters.from(Map.of("userId", "12345"));
String response = assistant.chat("Hello", parameters);
To embed the query with input_type=query (pairing with the ingestor's DOCUMENT, see
Query vs Document Embeddings), set the input type on the retriever:
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.embeddingInputType(EmbeddingInputType.QUERY)
.build();
The default is unchanged (no input type is sent). The EmbeddingModel must support the input_type parameter.
Web Search Content Retriever
WebSearchContentRetriever retrieves relevant Content from the web using a WebSearchEngine.
All supported WebSearchEngine integrations can be found here.
Here is an example:
WebSearchEngine googleSearchEngine = GoogleCustomWebSearchEngine.builder()
.apiKey(System.getenv("GOOGLE_API_KEY"))
.csi(System.getenv("GOOGLE_SEARCH_ENGINE_ID"))
.build();
ContentRetriever contentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(googleSearchEngine)
.maxResults(3)
.build();
Complete example can be found here.
SQL Database Content Retriever
SqlDatabaseContentRetriever is an experimental implementation of the ContentRetriever
that can be found in the langchain4j-experimental-sql module.
It uses the DataSource and an LLM to generate and execute SQL queries
for given natural language Query.
See javadoc of the SqlDatabaseContentRetriever for more information.
Here is an example.
Azure AI Search Content Retriever
AzureAiSearchContentRetriever is an integration with
Azure AI Search.
It supports full-text, vector, and hybrid search, as well as re-ranking.
It can be found in the langchain4j-azure-ai-search module.
Please refer to the AzureAiSearchContentRetriever Javadoc for more information.
Neo4j Content Retriever
Neo4jContentRetriever is an integration with the Neo4j graph database.
It converts natural language queries into Neo4j Cypher queries
and retrieves relevant information by running these queries in Neo4j.
It can be found in the langchain4j-community-neo4j-retriever module.
Elasticsearch Content Retriever
ElasticsearchContentRetriever is an integration with
Elasticsearch.
It supports full-text, vector, and hybrid search.
It can be found in the langchain4j-elasticsearch module.
Please refer to the ElasticsearchContentRetriever Javadoc for more information.
Query Router
QueryRouter is responsible for routing Query to the appropriate ContentRetriever(s).
Default Query Router
DefaultQueryRouter is the default implementation used in DefaultRetrievalAugmentor.
It routes each Query to all configured ContentRetrievers.
Language Model Query Router
LanguageModelQueryRouter uses the LLM to decide where to route the given Query.
Content Aggregator
The ContentAggregator is responsible for aggregating multiple ranked lists of Content from:
- multiple
Querys - multiple
ContentRetrievers - both
Default Content Aggregator
The DefaultContentAggregator is the default implementation of ContentAggregator,
which performs two-stage Reciprocal Rank Fusion (RRF).
Please see DefaultContentAggregator Javadoc for more details.
Re-Ranking Content Aggregator
The ReRankingContentAggregator uses a ScoringModel, like Cohere, to perform re-ranking.
The complete list of supported scoring (re-ranking) models can be found
here.
Please see ReRankingContentAggregator Javadoc for more details.
Content Injector
ContentInjector is responsible for injecting of Contents returned by ContentAggregator into the UserMessage.
Default Content Injector
DefaultContentInjector is the default implementation of ContentInjector that simply appends Contents
to the end of a UserMessage with the prefix Answer using the following information:.
You can customize how Contents are injected into the UserMessage in 3 ways:
- Override the default
PromptTemplate:
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentInjector(DefaultContentInjector.builder()
.promptTemplate(PromptTemplate.from("{{userMessage}}\n{{contents}}"))
.build())
.build();
Please note that PromptTemplate must contain {{userMessage}} and {{contents}} variables.
- Extend
DefaultContentInjectorand override one of theformatmethods - Implement a custom
ContentInjector
DefaultContentInjector also supports injecting Metadata entries from retrieved Content.textSegment():
DefaultContentInjector.builder()
.metadataKeysToInclude(List.of("source"))
.build()
In this case, TextSegment.text() will be prepended with the "content: " prefix,
and each value from Metadata will be prepended with a key.
The final UserMessage will look like this:
How can I cancel my reservation?
Answer using the following information:
content: To cancel a reservation, go to ...
source: ./cancellation_procedure.html
content: Cancellation is allowed for ...
source: ./cancellation_policy.html
Parallelization
When there is only a single Query and a single ContentRetriever,
DefaultRetrievalAugmentor performs query routing and content retrieval in the same thread.
Otherwise, an Executor is used to parallelize the processing.
By default, a modified (keepAliveTime is 1 second instead of 60 seconds) Executors.newCachedThreadPool()
is used, but you can provide a custom Executor instance when creating the DefaultRetrievalAugmentor:
DefaultRetrievalAugmentor.builder()
...
.executor(executor)
.build;
Accessing Sources
If you wish to access the sources (retrieved Contents used to augment the message)
when using AI Services,
you can easily do so by wrapping the return type in the Result class:
interface Assistant {
Result<String> chat(String userMessage);
}
Result<String> result = assistant.chat("How to do Easy RAG with LangChain4j?");
String answer = result.content();
List<Content> sources = result.sources();
When streaming, a Consumer<List<Content>> can be specified using the onRetrieved() method:
interface Assistant {
TokenStream chat(String userMessage);
}
assistant.chat("How to do Easy RAG with LangChain4j?")
.onRetrieved((List<Content> sources) -> ...)
.onPartialResponse(...)
.onCompleteResponse(...)
.onError(...)
.start();
Controlling what is stored in chat memory
When using a RetrievalAugmentor with AI Services,
you can control whether the augmented user message (with retrieved Content injected)
or the original user message is stored in chat memory.
This behavior is configured using the storeRetrievedContentInChatMemory option
on the AiServices builder.
Configuration
-
true(default)
Stores the augmentedUserMessage(original query plus retrieved content) in chat memory.
The same augmented message is also sent to the LLM. -
false
Stores only the originalUserMessage(without retrieved content) in chat memory.
The augmented message is still sent to the LLM during inference.
Storing only the original user message can be useful when you want to keep chat history concise and aligned with the user’s actual input, while still providing the LLM with retrieved context for answer generation.
Example
interface Assistant {
String chat(String userMessage);
}
ChatModel chatModel = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
MessageWindowChatMemory chatMemory =
MessageWindowChatMemory.withMaxMessages(10);
RetrievalAugmentor retrievalAugmentor =
DefaultRetrievalAugmentor.builder()
.contentRetriever(
EmbeddingStoreContentRetriever.from(embeddingStore, embeddingModel))
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(chatModel)
.chatMemory(chatMemory)
.retrievalAugmentor(retrievalAugmentor)
// Store only the original user message in chat memory
.storeRetrievedContentInChatMemory(false)
.build();
Examples
- Easy RAG
- Naive RAG
- Advanced RAG with Query Compression
- Advanced RAG with Query Routing
- Advanced RAG with Re-Ranking
- Advanced RAG with Including Metadata
- Advanced RAG with Metadata Filtering
- Advanced RAG with multiple Retrievers
- Advanced RAG with Web Search
- Advanced RAG with SQL Database
- Skipping Retrieval
- RAG + Tools
- Loading Documents